
Salvatore Di Lucia


°°°°°

Salvatore Di Lucia

si ha:


Ci sono due notazioni per scrivere una permutazione. Si considerino ad esempio una permutazione dell’insieme {1, 2, 3, 4, 5}. Si può scrivere sotto ad ogni numero la posizione in cui questo viene spostato:
Alternativamente, si può codificare la stessa permutazione sfruttando il teorema enunciato sopra, scrivendola come prodotto di cicli. Nel caso in esempio si ottiene (1 2 5)(3 4).
Con la notazione ciclica due permutazioni possono essere composte in modo agevole: ad esempio (1 2 5)(3 4) e (1 2 3) danno (1 2 5)(3 4)(1 2 3) = (1 5)(2 4 3). Si noti che composizione è fatta da destra verso sinistra. Per esempio, per vedere dove viene mandato 1 dalla composizione (1 2 5)(3 4)(1 2 3) si vede che (1 2 3) lo manda in 2, (3 4) non muove 2, e infine (1 2 5) manda 2 in 5. Quindi 1 va in 5.

I primi valori assunti dalla funzione in corrispondenza degli interi sono i seguenti:

Lo studio dell’asintotica di costituisce uno degli argomenti principali della teoria dei numeri analitica. Nel 1896, Hadamard e de la Vallée Poussin dimostrarono che
dove è il logaritmo integrale, confermando quanto ipotizzato da Legendre e Gauss. L’ipotesi di Riemann predice che valga una versione più precisa di tale risultato:
Definizione
Ad esempio, la funzione , definita su un qualsiasi aperto di , è armonica. Infatti:
Proprietà del valor medio
Inoltre, vale anche:
DimostrazioneSi fissi . Applicando il teorema della divergenza al campo vettoriale si ottiene:
Passando dalle coordinate cartesiane a quelle polari con:
si ha , e si verifica:
Calcolando l’integrale della derivata normale di e riscalando rispetto a si ottiene:
ed è possibile scambiare derivata e integrale:
Considerando l’integrale di superficie:
se ne deduce che per ogni si ha:
e passando al limite per si ottiene la prima uguaglianza. La seconda si ottiene integrando rispetto a .
Principio del massimoIl principio del massimo afferma che massimi e minimi stretti di una funzione armonica, se esistenti, vengono assunti al bordo. Più precisamente, si consideri una funzione armonica, dove è un dominio aperto e connesso di . Si supponga che esista in tale che per ogni . Allora è costante.
La dimostrazione usa la proprietà del valor medio. Sia e si consideri l’insieme . Per ipotesi, esso è non vuoto; inoltre, per la continuità di , è chiuso (nella topologia indotta) in quanto controimmagine di un insieme chiuso. Considerando la funzione , essa è negativa e armonica: si scelga una palla di raggio e si applichi la proprietà del valor medio a . Si ottiene:
Dato che l’integrando è non positivo, l’uguaglianza è soddisfatta se e solo se nella palla Quindi e è aperto in in quanto (ovvero , unione di insiemi aperti). è quindi contemporaneamente aperto e chiuso in , ma, poiché è connesso, e sono i soli sottoinsiemi aperti e chiusi. Ne consegue .
Armonicità delle funzioni complesse analiticheNel caso di funzioni di variabile complessa, il concetto di funzione armonica entra come particolare teorema soddisfatto dalle funzioni analitiche. Sia infatti:
una funzione analitica. Allora sia la sia la sono funzioni armoniche delle due variabili e :
Infatti, è sufficiente calcolare le derivate seconde delle equazioni di Cauchy-Riemann e confrontarle, ricordando che:
si ha:
Sommando la prima e l’ultima e la seconda e la terza e utilizzando il teorema di Schwarz sull’invertibilità delle derivate parziali:
Si ha così che date due funzioni e armoniche in un aperto che soddisfano le condizioni di Cauchy-Riemann allora è detta armonica coniugata di , ma non è vero il contrario. Una conseguenza di questo teorema è che una funzione è analitica in un aperto del piano complesso se e solo se è l’armonica coniugata di . Ciò significa che una funzione analitica può essere costruita a partire dall’assegnazione della sua parte reale e ricavando la sua parte immaginaria a meno di una costante.
Per un esempio di come calcolare l’armonica coniugata di una funzione si consideri la funzione . Questa funzione è armonica poiché:
Volendo trovare l’armonica coniugata , utilizzando le condizioni di Cauchy-Riemann si ha:
Si può integrare mantenendo fissata la variabile (considerandola come una costante):
dove è una funzione arbitraria dipendente da . Per utilizzare la condizione di Cauchy-Riemann si deriva ottenuta per integrazione rispetto a :
e si calcola la derivata dalla funzione di partenza:
Uguagliando si ricava il valore di :
dalla quale per integrazione:
dove è la costante di integrazione. Si ha dunque:
cioè si è ricavata l’armonica coniugata di a meno di una costante .In tal modo la funzione:
è una funzione analitica uguale a .

Definizioni
Funzioni reali

Nel caso di funzioni di una variabile reale, spesso la continuità è presentata come una proprietà del grafico: la funzione è continua se il suo grafico è formato da un’unica curva che non compia mai salti. Sebbene questa nozione possa essere usata nei casi più semplici per distinguere funzioni continue da funzioni discontinue, non è formalmente corretta, e può portare ad ambiguità o errori.
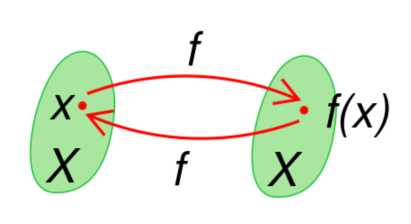
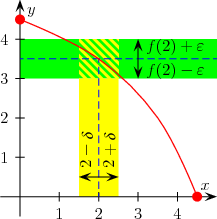
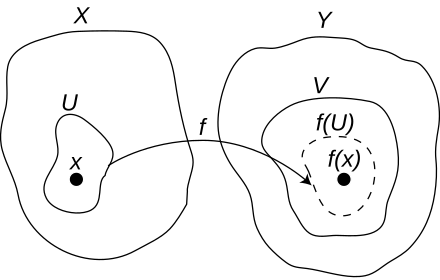
Una funzione si definisce continua nel punto del suo dominio se il suo limite per tendente a coincide con la valutazione della funzione in , ovvero con . In simboli:[1]
Tale definizione è usata maggiormente per funzioni definite su un intervallo della retta reale: infatti, essa ha senso solo se è un punto di accumulazione per il dominio di .
Essa è comunque estendibile anche nel caso di domini più complicati, che comprendono punti isolati: in essi, risulta continua per una “verità vuota” (dall’inglese vacuous truth).

Sono esempi di funzioni continue:

Sono esempi di funzioni non continue:
Proprietà delle funzioni continueSia una funzione continua a valori reali definita su un intervallo . Valgono:
Se è una funzione continua biiettiva a valori reali definita su un intervallo, allora è strettamente monotona e la funzione inversa è continua e strettamente monotona. L’implicazione non vale in generale per le funzioni il cui dominio non è un intervallo.[5]
Sia una funzione tra spazi metrici. Valgono:
Composizione
Come conseguenza di questa proprietà si hanno le seguenti:
In generale, l’inverso non è vero: ad esempio, se una funzione continua è somma di due funzioni, non è detto che entrambi gli addendi siano a loro volta funzioni continue. Ad esempio se
allora e non sono continue, ma
sono entrambe continue su tutto . Analogamente se
allora e non sono continue, ma
è continua su tutto .

Data una successione di funzioni continue tali che il limite:
esiste finito per ogni (convergenza puntuale), allora non è vero che è una funzione continua. Se però la successione converge uniformemente, allora il limite puntuale è continuo.[6]
Una funzione derivabile (o più in generale una funzione differenziabile) in un punto è sempre continua in quel punto. Non è vero l’inverso: esistono funzioni continue non derivabili, come ad esempio la funzione valore assoluto, continua in 0 ma non derivabile nello stesso punto. Esistono anche funzioni a variabile reale continue in tutti i punti del dominio e non derivabili in nessuno di essi, come la funzione di Weierstrass.
Una funzione continua è sempre integrabile secondo Riemann (e quindi anche secondo Lebesgue). Inoltre, ammette sempre primitive e ogni sua primitiva è continua. Viceversa, non tutte le funzioni integrabili sono continue: per esempio, sono integrabili tutte le funzioni costanti a tratti.
Continuità per successioniUna funzione a valori reali è continua per successioni in se, per ogni successione a valori nel dominio della funzione e convergente a , la successione converge a .
Questa formulazione di continuità è dovuta ad Eduard Heine.
Una funzione continua è sempre continua per successioni, mentre, al contrario è possibile dare esempi di funzioni continue per successioni, ma non continue. L’inverso vale solo se il dominio è uno spazio sequenziale, come lo sono gli spazi primo-numerabili[8] e dunque in particolare gli spazi metrici: in questo caso, quindi, le due definizioni si possono considerare equivalenti.[9]
Continuità a sinistra e a destra
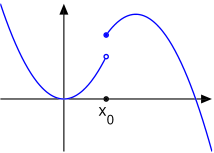
Una funzione reale si dice continua a destra in se:
dove il limite è inteso solo come limite destro.
Una funzione si dice continua a sinistra in se:
Una funzione è continua in un punto se e solo se è ivi continua a destra e a sinistra.
Queste proprietà non sono estendibili a funzioni a più di una variabile, in quanto nel piano, nello spazio, e generalmente in quando non esiste relazione d’ordine, ovvero non è possibile definire una “destra” o una “sinistra”.
Semicontinuità
Una funzione definita su uno spazio topologico a valori reali si dice semicontinua inferiormente in se per ogni esiste un intorno di tale che per ogni , si ha:
Se invece vale, per ogni :
la funzione viene detta semicontinua superiormente in .
Se la prima (o rispettivamente la seconda) proprietà vale in ogni punto del dominio, si dice che la funzione è semicontinua inferiormente (o rispettivamente semicontinua superiormente).
La semicontinuità (sia inferiore che superiore), è una proprietà più debole della continuità: esistono funzioni semicontinue ma non continue. Viceversa, una funzione è continua se e solo se è sia semicontinua inferiormente che semicontinua superiormente.
Continuità separata
Nel caso di funzioni di più variabili, è possibile definire una condizione più debole di continuità, detta continuità separata: una funzione è continua separatamente in un punto rispetto a una delle variabili se è continua la funzione di una variabile dipendente solo dal parametro , lasciando le restanti variabili fissate al valore assunto nel punto in esame.
Continuità uniformeUna condizione più forte (e globale) di continuità è quella di continuità uniforme: una funzione continua tra due spazi metrici si dice uniformemente continua se il parametro della definizione non dipende dal punto considerato, ovvero se è possibile scegliere un che soddisfi la definizione per tutti i punti del dominio.
Più precisamente, una funzione è uniformemente continua se, per ogni esiste un tale che, comunque presi due punti e nel dominio di che distano per meno di , allora le loro immagini e distano per meno di .[5]
Equicontinuità
Quando gli elementi di un insieme di funzioni continue hanno il medesimo modulo di continuità, si parla di insieme equicontinuo. Nello specifico, Siano e due spazi metrici e una famiglia di funzioni definite da in . La famiglia è equicontinua nel punto se per ogni esiste tale che per tutte le e per ogni tali che .
La famiglia è equicontinua (in tutto ) se è equicontinua in ogni suo punto. La famiglia è uniformemente equicontinua se per ogni esiste tale che per tutte le e per ogni coppia di punti e in tali che .
Più in generale, quando è uno spazio topologico, un insieme di funzioni da in è equicontinuo nel punto se per ogni il punto possiede un intorno tale che:
Tale definizione è spesso utilizzata nell’ambito degli spazi vettoriali topologici.
L’insieme di tutte le funzioni continue su un dominio fissato e a valori reali:
può essere dotato di una struttura di spazio vettoriale ponendo per e in tale insieme:
e per numero reale:
Lo spazio vettoriale così definito è detto spazio delle funzioni continue su .
Se il dominio è compatto (e quindi per tutte le funzioni in vale il teorema di Weierstrass) nello spazio può essere definita una norma ponendo:
detta norma uniforme o norma del sup.
La coppia costituita dallo spazio e dalla norma uniforme individua uno spazio di Banach.
In matematica , le funzioni pari e le funzioni dispari sono funzioni che soddisfano delle particolari relazioni di simmetria riguardo ai valori negativi. Sono importanti in molte aree dell’analisi matematica , in particolare nella teoria delle serie di potenze e delle serie di Fourier .
Funzioni pariSia una funzione a valori reali di variabile reale e sia il suo dominio. Allora è pari se per ogni vale l ‘ equazione [1] :
Geometricamente, il grafico di una funzione pari è simmetrico rispetto all’asse .
Il nome pari deriva dal fatto che le serie di Taylor di una funzione pari centrate nell’origine contiene solo potenze pari.
Esempi di funzioni pari sono
Esempio pratico:
Funzioni dispariAncora sia una funzione a valori reali di variabile reale e sia il suo dominio. Allora è dispari se per ogni sussiste l ‘ equazione [2] :
Geometricamente, il grafico di una funzione dispari è simmetrico rispetto all’origine degli assi.
Il nome dispari deriva dal fatto che le serie di Taylor di una funzione dispari centrate nell’origine contengono solo potenze dispari.
Esempi di funzioni dispari sono
Esempio:
Alcune informazioniMentre l’unione degli interni pari e dispari corrisponde all’intero insieme degli interni , l’unione delle funzioni pari e dispari su un intervallo è incluso propriamente nell’insieme delle funzioni su quell’intervallo. Una funzione pertanto può essere pari, oppure dispari, oppure essere né pari né dispari.
Proprietà fondamentali
Serie
e quindi:
Inoltre dato che l’unica funzione pari e dispari è lo spazio delle funzioni pari è in somma diretta con quello delle funzioni dispari.
Polinomio
In matematica un polinomio è un’espressione composta da costanti e variabili combinate usando soltanto addizione, sottrazione e moltiplicazione, gli esponenti delle variabili sono valori interi non negativi. In altre parole, un polinomio tipico, cioè ridotto in forma normale, è la somma algebrica di alcuni monomi non simili tra loro, vale a dire con parti letterali diverse.
Ad esempio:
è la somma di tre monomi.
Ciascun monomio viene chiamato termine del polinomio.
Le costanti sono anche chiamate “coefficienti” e sono tutte elementi di uno stesso insieme numerico o di un anello.
Quando valutati in un opportuno dominio, i polinomi possono essere interpretati come funzioni.
Ad esempio, il polinomio
definisce una funzione reale di variabile reale.
Quando questo ha senso, le radici del polinomio sono definite come l’insieme di quei valori che, sostituiti alle variabili, danno all’espressione polinomiale il valore nullo.
Ad esempio, ha come radici i valori e , poiché sostituendoli nell’espressione del polinomio si ha
I polinomi sono oggetti matematici di fondamentale importanza, alla base soprattutto dell’algebra, ma anche dell’analisi e della geometria analitica.
NomenclaturaUn polinomio si dice:
, quando è stato semplificato, sono stati accorpati i suoi termini simili e sono stati eliminati gli eventuali monomi nulli. Ad esempio:
se è la somma di monomi dello stesso grado. Ad esempio:
è omogeneo di grado .
rispetto ad una variabile, se osservando tutti i termini del polinomio di quella certa variabile e partendo dal termine di grado più elevato rispetto a quella variabile il polinomio contiene tutti i termini di grado inferiore fino a zero. Esempio di un polinomio completo rispetto a :
Due polinomi sono considerati uguali se, dopo essere stati ridotti in forma normale, hanno gli stessi termini, a meno dell’ordine. Quindi i polinomi seguenti sono uguali:
Il grado di un polinomio non nullo e ridotto in forma normale è il massimo grado dei suoi monomi, mentre il grado parziale rispetto ad una variabile è il grado risultante vedendo tutte le altre variabili come coefficienti. Quindi
ha grado due, mentre ha gradi parziali uno rispetto sia a che a .
Si dicono coefficienti di un polinomio i coefficienti dei suoi singoli termini. Quindi i coefficienti di sono rispettivamente , e : il coefficiente in un monomio è solitamente sottinteso.
Il termine noto di un polinomio ridotto in forma normale è l’unico monomio (se esiste) di grado zero, cioè non contenente variabili. Se non esiste un tale monomio, il termine noto è considerato generalmente inesistente o uguale a zero, secondo il contesto. Ad esempio, in
il termine noto è l’ultimo monomio: .
Operazioni con i polinomiDue polinomi possono essere sommati, sottratti, e moltiplicati usando le usuali proprietà commutativa, associativa e distributiva delle operazioni di somma e prodotto. Ad esempio, se
allora la somma ed il prodotto di p e q sono rispettivamente
Somme e prodotti di polinomi danno come risultato un nuovo polinomio.
Esempi:
Prodotto di un polinomio per uno scalareIl grado del prodotto di un polinomio per un numero scalare (diverso da zero) è uguale al grado del polinomio:
Esempio:
Si noti che questo non è sempre vero per i polinomi definiti su un anello che contiene un divisore di zero. Ad esempio, in , , ma . L’insieme dei polinomi aventi coefficienti da un dato campo F e grado minore o uguale a n, forma uno spazio vettoriale (questo insieme non è un anello, e non è chiuso, come mostrato in precedenza).
Moltiplicazione di due polinomiIl grado del prodotto di due polinomi definiti su un campo -(oggetto in cui sono definite le operazioni di somma e prodotto, con certe proprietà)- oppure su un dominio d’integrità, è pari alla somma dei gradi dei due polinomi:
Es.:
Si noti che ciò non è sempre vero per i polinomi definiti su un anello arbitrario. Ad esempio, in , , ma .
Composizione di due polinomiIl grado della composizione di due polinomi e a coefficienti non costanti è uguale al prodotto dei rispettivi gradi:
Es.:
Si noti che ciò non è sempre vero per i polinomi definiti su un anello arbitrario. Ad esempio, in , , ma .
Grado del polinomio zero
e
può essere considerato anche come polinomio in soltanto, dando a il ruolo di un valore costante. Alternativamente, può essere visto come polinomio in soltanto. Le proprietà dei polinomi che ne risultano possono essere molto diverse tra loro: qui ad esempio ha grado rispetto a , e solo rispetto a . Ad esempio, il polinomio
è di grado , ma se visto soltanto nelle singole variabili o o ha grado rispettivamente , e .
con diverso da zero. Con questa scrittura, è il termine noto e è il grado. si dice coefficiente direttore.
Un tale polinomio è
Radici di un polinomio
Una radice di un polinomio in una sola variabile è un numero tale che
cioè tale che, sostituito a , rende nulla l’espressione. Quindi se
il numero è radice se
Nel caso di polinomi a coefficienti reali l’insieme delle radici reali di un polinomio si può visualizzare sul piano cartesiano come l’intersezione del grafico della funzione polinomiale con l’asse delle ascisse.
In un dominio, un polinomio di grado può avere al più radici distinte. Esistono polinomi senza radici reali, come ad esempio
poiché per ogni reale. D’altra parte, per il teorema fondamentale dell’algebra ogni polinomio complesso ha esattamente radici complesse, contate con molteplicità.
°°°°°
Esempi
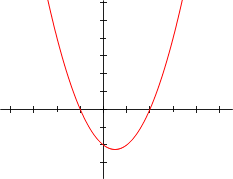 Polinomio di grado 2:
f(x) = x2 – x – 2 = (x+1)(x-2) |
 Polinomio di grado 3:
f(x) = x3/5 + 4x2/5 – 7x/5 – 2 = 1/5 (x+5)(x+1)(x-2) |
 Polinomio di grado 4:
f(x) = 1/14 (x+4)(x+1)(x-1)(x-3) + 0.5 |
 Polinomio di grado 5:
f(x) = 1/20 (x+4)(x+2)(x+1)(x-1)(x-3) + 2 |
DerivataUna funzione polinomiale a coefficienti reali
è derivabile e la sua derivata è ancora un polinomio,
Ragionando quindi induttivamente, si può quindi affermare che le funzioni polinomiali sono infinitamente derivabili (o lisce) e che la derivata (n+1)-esima di un polinomio di grado è la funzione nulla. In realtà esse sono anche funzioni analitiche.
°°°°°
Dato un anello , il simbolo
denota l’insieme di tutti i polinomi nelle variabili con coefficienti in . Ad esempio, può essere un campo come quello dei numeri reali o complessi.
L’insieme risulta essere anch’esso un anello, l’anello dei polinomi in variabili con coefficienti in . Lo studio delle proprietà di questo anello è una parte importante dell’algebra e della geometria algebrica.
Se è un campo, l’anello dei polinomi è un’algebra su , e quando è anche un anello euclideo, nel senso che i polinomi possono essere divisi con quoziente e resto come i numeri interi (se questo non è vero poiché l’anello di polinomi non è un dominio ad ideali principali).
Esempi
Derivata formale
Il calcolo della derivata di un polinomio si estende come definizione di derivata (chiamata derivata formale) nel caso in cui il polinomio abbia coefficienti in un anello , anche in assenza del calcolo infinitesimale. Molte delle proprietà della derivata si estendono anche alla derivata formale.
Casi particolari
Per le relazioni radici/coefficienti un polinomio di secondo grado si può scrivere nella forma
dove
Allora
Caso particolare n=3Per le relazioni radici/coefficienti un polinomio di terzo grado si può scrivere nella forma
dove
Allora
Funzione razionale
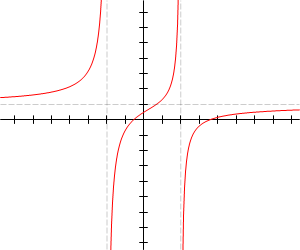
Ad esempio:
Asintoti
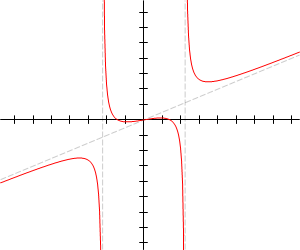
Poli
Decomposizione in fratti semplici
Per ogni fattore che ha la forma : si considerano le frazioni , mentre per ogni fattore che ha la forma : si considerano le frazioni:
Se si applica la decomposizione fin dove è possibile si ottiene che il denominatore di ogni termine è una potenza di un polinomio non fattorizzabile e il numeratore è un polinomio di grado inferiore di quello del polinomio non fattorizzabile.°°°°°Funzione differenziabile
In matematica, in particolare in analisi matematica e geometria differenziale, una funzione differenziabile in un punto è una funzione che può essere approssimata a meno di un resto infinitesimo da una trasformazione lineare in un intorno abbastanza piccolo di quel punto. Affinché ciò si verifichi è necessario che tutte le derivate parziali calcolate nel punto esistano, cioè se è differenziabile allora è derivabile nel punto poiché esistono e sono finiti i limiti dei rapporti incrementali direzionali. Il concetto di differenziabilità permette di generalizzare il concetto di funzione derivabile a funzioni vettoriali di variabile vettoriale, e la differenziabilità di una funzione permette di individuare per ogni punto del suo grafico un iperpiano tangente.Una funzione può essere differenziabile volte, e si parla in questo caso di funzione di classe . Una funzione differenziabile infinite volte è inoltre detta liscia. Nell’analisi funzionale le distinzioni fra le varie classi sono molto importanti, mentre in altri settori della matematica queste differenze sono meno tenute in considerazione, e spesso si usa impropriamente il termine “funzione differenziabile” per definire una funzione liscia.Definizione

Una funzione:
definita su un insieme aperto dello spazio euclideo è detta differenziabile in un punto del dominio se esiste una applicazione lineare:
tale che valga l’approssimazione:
dove si annulla, con ordine di infinitesimo maggiore di 1, all’annullarsi dell’incremento . Tale condizione si può scrivere in modo equivalente:
Se la funzione è differenziabile in , l’applicazione è rappresentata dalla matrice jacobiana .Il vettore:
si chiama differenziale (esatto) di in ed viene detto derivata o anche derivata totale della funzione .La funzione è infine differenziabile se lo è in ogni punto del dominio.[2] In particolare, il teorema del differenziale totale afferma che una funzione è differenziabile in un punto se tutte le derivate parziali esistono in un intorno del punto per ogni componente della funzione e se sono inoltre funzioni continue. Se inoltre l’applicazione che associa a è continua, la funzione si dice differenziabile con continuità.Nel caso di una funzione di una variabile definita su un intervallo aperto dell’asse reale, essa è detta differenziabile in se esiste un’applicazione lineare tale che:
ed in tal caso si ha:
Matrice jacobianaSe una funzione è differenziabile in un punto allora tutte le derivate parziali calcolate nel punto esistono, ma non vale il viceversa. Tuttavia, se tutte le derivate parziali esistono e sono continue in un intorno del punto allora la funzione è differenziabile nel punto, ovvero è di classe .Dette e le basi canoniche di e rispettivamente, si ha:
L’applicazione lineare è quindi rappresentata nelle basi canoniche da una matrice , detta matrice jacobiana di in .Il -esimo vettore colonna della matrice jacobiana è dato dalla precedente relazione, e si ha:[5]
A seconda delle dimensioni e , il jacobiano ha diverse interpretazioni geometriche:
Differenziabilità in analisi complessaSia un sottoinsieme aperto del piano complesso . Una funzione è differenziabile in senso complesso (-differenziabile) in un punto di se esiste il limite:
Il limite va inteso in relazione alla topologia del piano. In altre parole, per ogni successione di numeri complessi che convergono a il rapporto incrementale deve tendere allo stesso numero, indicato con . Se è differenziabile in senso complesso in ogni punto di , essa è una funzione olomorfa su . Si dice inoltre che è olomorfa nel punto se è olomorfa in qualche intorno del punto, e che è olomorfa in un insieme non aperto se è olomorfa in un aperto contenente .
La relazione tra la differenziabilità di funzioni reali e funzioni complesse è data dal fatto che se una funzione complessa è olomorfa allora e possiedono derivata parziale prima rispetto a e e soddisfano le equazioni di Cauchy-Riemann:
In modo equivalente, la derivata di Wirtinger di rispetto al complesso coniugato di è nulla.
Proprietà delle funzioni differenziabili
ApprossimazioniDa un punto di vista informale, una funzione differenziabile è una funzione tale da apparire sempre più simile ad una trasformazione affine quando viene vista ad ingrandimenti sempre maggiori. La trasformazione affine che approssima in un intorno di è la funzione:
Per verificarlo, si consideri un intorno di di raggio .
Se si effettua uno zoom sul grafico di in modo che l’intorno ci appaia di raggio , la distanza che si vede tra la funzione e la funzione affine che la approssima in corrispondenza del punto è pari a:
dove la divisione per corrisponde al riscalamento dovuto allo “zoom” che si sta operando sull’intorno. Quindi la massima distanza che si vede nell’intorno riscalato è:
ora si può dimostrare che dalla definizione di differenziabilità di si deduce che:
il che significa che quello che si osserva ingrandendo progressivamente il grafico di e della sua approssimazione affine intorno a è che questi tendono a coincidere. Viceversa, la relazione implica direttamente la differenziabilità di .
°°°°°
In matematica, una funzione liscia in un punto del suo dominio è una funzione che è differenziabile infinite volte nel punto, o equivalentemente, che è derivabile infinite volte nel punto rispetto ad ogni sua variabile (per il teorema del differenziale infatti, una funzione è differenziabile in un punto se le sue derivate parziali sono ivi continue). Se una funzione è liscia in tutti i punti di un insieme , si dice che essa è di classe su , e si scrive .
Sia una funzione reale di variabile reale definita su un dominio , e si supponga che sia liscia sull’intervallo aperto . Preso allora un punto , è possibile approssimare la funzione attorno a quel punto grazie al teorema di Taylor:
dove la quantità è un resto tale che:
Poiché la funzione è liscia, questa approssimazione vale per ogni . In particolare, è possibile valutare la serie di Taylor della funzione prendendo il limite per :
A differenza di quanto ci si potrebbe aspettare, questa serie in generale non converge a : se la convergenza (puntuale) è verificata, si dice che è analitica in , e se è l’insieme dei punti in cui è analitica si scrive . Poiché ogni funzione analitica è in particolare liscia, vale la relazione insiemistica:
Un discorso analogo può essere fatto per le funzioni a più variabili reali.

Nel caso di funzioni complesse di variabile complessa, la liscezza in un punto (o su un insieme) discende direttamente dall’olomorfia della funzione in tale punto (o su tale insieme). Per tale motivo si parla indifferentemente di “liscezza” o di “derivabilità” di una funzione complessa. In effetti, è possibile dimostrare che una funzione complessa olomorfa su un dominio è ivi addirittura analitica (vedi Equazioni di Cauchy-Riemann).
Siano e varietà differenziabili e un punto di . Una funzione è detta differenziabile in (oppure liscia o di classe in ) se esistono una carta in ed una carta in tali che e la composizione:
sia liscia in un intorno di . Tale definizione non dipende dalle carte scelte: prendendo infatti altre carte e la composizione rimane liscia in un intorno di .
è differenziabile (liscia, di classe ) se lo è per ogni in . Se inoltre è invertibile con inversa liscia allora si dirà un diffeomorfismo. Lo studio delle proprietà invarianti per diffeomorfismi è oggetto della topologia differenziale.
È spesso utile costruire funzioni lisce che sono nulle al di fuori di un dato intervallo, ma non all’interno dello stesso (funzioni a supporto compatto). Tale proprietà non si può mai avere per una serie di potenze[1], il che fornisce un’ulteriore dimostrazione del divario tra le funzioni lisce e funzioni analitiche.
In matematica, una funzione analitica è una funzione localmente espressa da una serie di potenze convergente. Spesso il termine “funzione analitica” è utilizzato come sinonimo di funzione olomorfa, sebbene quest’ultimo si utilizzi più spesso per le funzioni complesse (tutte le funzioni olomorfe sono funzioni analitiche complesse e viceversa).[1] Una funzione è analitica se e solo se, preso comunque un punto appartenente al dominio della funzione, esiste un suo intorno in cui la funzione coincide col suo sviluppo in serie di Taylor.
Le funzioni analitiche possono essere viste come un ponte fra i polinomi e le funzioni generiche. Esistono le funzioni analitiche reali e le funzioni analitiche complesse: simili in alcuni aspetti, differenti in altri. Funzioni di questo tipo sono infinitamente derivabili, ma le funzioni analitiche complesse esibiscono proprietà che generalmente non appartengono alle funzioni analitiche reali.
DefinizioneUna funzione è analitica su un insieme aperto della retta reale se per ogni in si può scrivere come:[2]
dove i coefficienti sono numeri reali e la serie è convergente in un intorno di .
In alternativa, una funzione analitica è una funzione infinitamente derivabile, ossia una funzione liscia, tale che la sua serie di Taylor
in ogni punto appartenente al dominio, converge a per in un intorno di .
L’insieme di tutte le funzioni analitiche reali appartenenti ad un dato insieme si denota di solito come .
Una funzione definita in un qualche sottoinsieme della retta reale, si dice essere reale analitica al punto se esiste un intorno di nel quale è reale analitica.
La definizione di funzione analitica complessa è ottenuta sostituendo dappertutto “reale” con “complesso.
Proprietà delle funzioni analiticheTra le principali proprietà che caratterizzano le funzioni analitiche ci sono le seguenti:
Un polinomio non può valere zero in troppi punti a meno che non sia il polinomio nullo (più precisamente, il numero di zeri è al massimo pari al grado del polinomio). Un’affermazione simile ma più debole vale per le funzioni analitiche. Se l’insieme degli zeri di una funzione analitica ha un punto di accumulazione all’interno del suo dominio, allora è nulla su tutta la componente connessa del dominio che contiene il punto di accumulazione.
Più formalmente questa affermazione può essere espressa nel modo seguente. Se è una successione di numeri distinti tale che per ogni e questa successione converge a un punto nel dominio , allora è identicamente zero nella componente connessa di contenente . Inoltre, se tutte le derivate di una funzione analitica sono nulle in un punto, vale ancora la conclusione precedente.
Queste affermazioni implicano che le funzioni analitiche siano ancora abbastanza rigide, nonostante il loro maggior numero di gradi di libertà rispetto ai polinomi.
Tutte le funzioni analitiche (reali o complesse) in un punto sono infinitamente derivabili in , dove è il raggio di convergenza della serie. Inoltre, si dimostra che nella stessa regione la derivata della funzione coincide con la serie delle derivate (la serie derivata), ovvero se:
allora:
Allo stesso modo, essendo il limite uniforme di una successione di funzioni continue (polinomi), ogni funzione analitica è continua (e quindi integrabile) su tutto il suo insieme di convergenza, e la sua primitiva è la serie primitiva. In altre parole, se:
si ha:
Non tutte le funzioni reali lisce sono analitiche; ad esempio la funzione definita come:
è liscia in ma non è analitica in 0. Questo può essere espresso dall’implicazione (non invertibile):
La situazione è molto diversa nel caso delle funzioni analitiche complesse. Si può dimostrare che tutte le funzioni olomorfe su un insieme aperto sono analitiche. Di conseguenza, in analisi complessa, il termine “funzione analitica” è un sinonimo di funzione olomorfa.
Se una funzione reale di variabile reale liscia definita su un aperto ha tutte le derivate maggiorabili dai termini di una successione geometrica (di ragione fissata) su un intorno di un dato punto, allora la funzione è analitica in quell’intorno. Formalmente, sia ed appartenente a e sia . Se esistono tali che:
allora:
In particolare, se una funzione ha tutte le derivate limitate da una stessa costante su un intervallo, allora è ivi analitica (basta porre nell’enunciato precedente). Questo mostra che funzioni come seno, coseno, esponenziale[3], funzioni iperboliche possono essere espresse in termini di serie di potenze sull’intero asse reale:
Dato che la funzione è liscia, è possibile scriverne la formula di Taylor arrestata all’ordine (resto secondo Lagrange):
Se si muove nell’intorno di di raggio si può usare la maggiorazione (in valore assoluto) garantita dall’ipotesi:
cioè la serie converge puntualmente a sull’intervallo , Q.E.D.
Inoltre, se una funzione analitica complessa è definita in una palla aperta intorno a un punto , la sua espansione in serie di potenze in è convergente nell’intera palla. Questo non è vero in generale per le funzioni analitiche reali. Una palla aperta nel piano complesso è un disco bidimensionale, mentre sulla retta reale è un intervallo.
Ogni funzione analitica reale su un certo insieme aperto della retta reale può essere estesa a una funzione analitica complessa su un certo insieme aperto del piano complesso. Comunque non tutte le funzioni analitiche reali definite sull’intera retta reale possono essere estese a una funzione complessa definita sull’intero piano complesso. La funzione definita nel paragrafo precedente è un controesempio.
Si possono definire le funzioni analitiche in più variabili tramite le serie di potenze in queste variabili. Le funzioni analitiche in più variabili hanno alcune delle proprietà delle funzioni analitiche a una variabile. Comunque, soprattutto nel caso delle funzioni analitiche complesse, si trovano nuovi e interessanti fenomeni in più dimensioni.
In matematica, una funzione olomorfa (composizione delle parole greche “holos”, tutto e “morphos“, forma; in riferimento alla capacità della derivata di rimanere uguale a sé stessa nelle trasformazioni[1]) è una funzione definita su un sottoinsieme aperto del piano dei numeri complessi con valori in che è differenziabile in senso complesso in ogni punto del dominio. Le funzioni olomorfe sono tra gli oggetti principali dell’analisi complessa. Possono essere scritte ovunque come serie di potenze convergenti ovvero sono analitiche, ed il termine “funzione analitica” è utilizzato come sinonimo di funzione olomorfa.[2]
La differenziabilità in senso complesso di una funzione complessa è una condizione molto più stringente della differenziabilità reale in quanto implica che la funzione sia infinite volte differenziabile e che possa essere completamente individuata dalla sua serie di Taylor. In alcuni testi le funzioni olomorfe (e le loro derivate) definite su un aperto sono dette funzioni analitiche.
In tale contesto si definisce biolomorfismo fra due insiemi aperti di una funzione olomorfa che sia iniettiva, suriettiva, e la cui inversa è anch’essa olomorfa.
Sia un sottoinsieme aperto del piano complesso . Una funzione è differenziabile in senso complesso (-differenziabile) in un punto di se esiste il limite:[3]
Il limite va inteso in relazione alla topologia del piano. In altre parole, per ogni successione di numeri complessi che convergono a il rapporto incrementale deve tendere allo stesso numero, indicato con .
La funzione è olomorfa in se è differenziabile in senso complesso in ogni punto dell’aperto . Si dice inoltre che è olomorfa nel punto se è olomorfa in qualche intorno del punto e più in generale che è olomorfa in un insieme non aperto se è olomorfa in un aperto contenente .
La relazione tra la differenziabilità di funzioni reali e funzioni complesse è data dal fatto che se una funzione complessa
è olomorfa allora e possiedono derivate parziali prime rispetto a e , e tali derivate soddisfano le equazioni di Cauchy-Riemann:
In modo equivalente, la derivata di Wirtinger di rispetto al complesso coniugato di è nulla.
Tramite l’identificazione standard di con , una funzione olomorfa è in particolare una funzione differenziabile da un aperto di in . Non è però vero l’opposto: una funzione differenziabile non è necessariamente olomorfa. Le equazioni di Cauchy-Riemann descrivono una condizione necessaria e sufficiente affinché una funzione differenziabile sia olomorfa.
Le usuali regole di derivazione definite solitamente in ambito reale restano valide nel campo complesso.[3]
Una funzione olomorfa avente derivata sempre diversa da zero è una mappa conforme, una mappa che non cambia gli angoli (ma può cambiare aree e lunghezze).
Infatti una funzione olomorfa con derivata non nulla è una funzione localmente approssimabile da una funzione lineare complessa del tipo
per qualche numero complesso . Le mappe lineari di questo tipo sono conformi; infatti, scrivendo , si ottiene
e quindi la moltiplicazione per è geometricamente la composizione di una rotazione di angolo e di una omotetia di fattore : entrambe queste operazioni sono mappe conformi.
Funzioni intere.Tutte le funzioni polinomiali nella variabile complessa con coefficienti complessi sono olomorfe sull’intero , cioè sono funzioni intere.
Sono funzioni intere anche la funzione esponenziale complessa e le funzioni trigonometriche nella . (In effetti le funzioni trigonometriche sono esprimibili come composizioni di varianti della funzione esponenziale attraverso la formula di Eulero).
Il ramo principale della funzione logaritmo è olomorfo sul piano complesso privato del semiasse reale negativo:
La funzione radice quadrata può essere definita come
e di conseguenza è olomorfa in tutti i punti del piano complesso nei quali lo è la funzione logaritmo.
Funzioni non olomorfeGli esempi base di funzioni complesse non olomorfe sono la coniugazione complessa, il passaggio alla parte reale e la funzione valore assoluto.
centrata in è convergente sul disco aperto di raggio centrato in
e coincide con su questo disco. In altre parole, una funzione olomorfa è localmente esprimibile come serie di potenze.
La serie di Taylor può convergere su un disco più grande, non necessariamente contenuto nel dominio: questo accade ad esempio nella funzione logaritmo definita sopra, qualora si prenda un punto vicino al semiasse reale. Questo fenomeno è chiamato prolungamento analitico.
Formula integrale di CauchyLa formula integrale di Cauchy è uno strumento molto potente in analisi complessa, che non ha analogie nell’analisi reale. Tale formula mette in relazione il valore di una funzione in un punto con un integrale lungo una curva che lo racchiude.
Teorema di Liouville
definita su un aperto di . Questa è olomorfa in un punto se è localmente sviluppabile (all’interno di un polidisco, cioè all’interno di un prodotto cartesiano di dischi centrato nel punto) come serie di potenze convergente. Si osserva che questa condizione è più forte delle equazioni di Cauchy-Riemann; in effetti essa può essere espressa nella forma seguente:
Una funzione di più variabili complesse a valori complessi è olomorfa se e solo se soddisfa le equazioni di Cauchy-Riemann ed è localmente a quadrato sommabile.
°°°°°
In matematica, le funzioni antiolomorfe (chiamate anche funzioni antianalitiche) sono una famiglia di funzioni strettamente collegate alle funzioni olomorfe ma distinte da quest’ultime.
Una funzione definita in un insieme aperto nel piano complesso è detta antiolomorfa se è derivabile in senso reale (vale a dire, se e sono funzioni reali derivabili) e la sua derivata rispetto a è identicamente nulla in . Questa definizione si contrappone ad una delle definizioni equivalenti di funzione olomorfa, dove viene richiesto che sia derivabile in senso reale e la sua derivata rispetto a sia nulla.
Dalla relazione segue che è antiolomorfa se e solo se è olomorfa.
Osserviamo che se è una funzione olomorfa in un insieme aperto , allora è una funzione antiolomorfa in , dove è la riflessione rispetto all’asse x dell’insieme ; in altre parole, è l’insieme dei complessi coniugati degli elementi di . Quindi ogni funzione antiolomorfa può essere ottenuta in questo modo partendo da una funzione olomorfa. Ciò implica che una funzione è antiolomorfa se e solo se può essere espansa in serie di potenze nella variabile in un intorno di ogni punto del suo dominio.
Se una funzione è sia olomorfa che antiolomorfa allora è costante in ogni componente connessa del suo dominio. Per definizione, una funzione che dipenda sia da che da non può essere olomorfa né antiolomorfa.
°°°°°
In matematica, in particolare in analisi complessa, si definisce funzione meromorfa su un sottoinsieme aperto del piano complesso una funzione che è olomorfa su tutto ad esclusione di un insieme di punti isolati che sono poli della funzione stessa.
Ogni funzione meromorfa su può essere espressa come rapporto di due funzioni olomorfe (con la funzione denominatore diversa dalla costante 0) definite sull’intero : i poli della funzione meromorfa si ritrovano allora come zeri del denominatore.

Da un punto di vista algebrico, l’insieme delle funzioni meromorfe sopra un dominio connesso munito delle operazioni di somma e prodotto è il campo delle frazioni del dominio di integrità costituito dall’insieme delle funzioni olomorfe nell’intero . In parole povere, le funzioni meromorfe stanno alle olomorfe come le funzioni razionali fratte stanno alla funzioni razionali intere, come sta a .
non è meromorfa sull’intero piano complesso, in quanto non può essere definita sull’intero piano complesso ad eccezione di un insieme isolato di punti; può invece essere definita come funzione meromorfa (e in particolare olomorfa) sul piano privato dell’intera semiretta dei reali non positivi.
Integrale


Definizione
Integrale di Riemann-Darboux
Integrale di Lebesgue
Sia un vettore nel campo reale. Un insieme del tipo:
è detto -cella. Sia definita su una funzione continua a valori reali, e si definisca:
Tale funzione è definita su ed è a sua volta continua a causa della continuità di . Iterando il procedimento si ottiene una classe di funzioni continue su che sono il risultato dell’integrale di rispetto alla variabile sull’intervallo . Dopo volte si ottiene il numero:
Si tratta dell’integrale di su rispetto a , e non dipende dall’ordine con il quale vengono eseguite le integrazioni.
In particolare, sia . Allora si ha:
Inoltre, sia una funzione a supporto compatto e si ponga che contenga il supporto di . Allora è possibile scrivere:
Nell’ambito della teoria dell’integrale di Lebesgue è possibile estendere questa definizione a insiemi di funzioni più ampi.
Una proprietà di notevole importanza dell’integrale di una funzione in più variabili è la seguente.
Siano:
Allora si ha:
L’integrando ha un supporto compatto grazie all’invertibilità di , dovuta all’ipotesi per ogni che garantisce la continuità di in per il teorema della funzione inversa.
Dato un campo scalare , si definisce l’integrale di linea (di prima specie) su una curva , parametrizzata da , con , come:[10]
dove il termine indica che l’integrale è effettuato su un’ascissa curvilinea. Se il dominio della funzione è , l’integrale curvilineo si riduce al comune integrale di Riemann valutato nell’intervallo . Alla famiglia degli integrali di linea appartengono anche gli integrali ellittici di prima e di seconda specie, questi ultimi impiegati anche in ambito statistico per il calcolo della lunghezza della curva di Lorenz.
Similmente, per un campo vettoriale , l’integrale di linea (di seconda specie) lungo una curva , parametrizzata da con , è definito da:[11]
Una condizione sufficiente ai fini dell’integrabilità è che una funzione definita su un intervallo chiuso e limitato sia continua: una funzione continua definita su un compatto, e quindi continua uniformemente per il teorema di Heine-Cantor, è integrabile.
| Dimostrazione |
|---|
| Si suddivida l’intervallo in sottointervalli di uguale ampiezza:
Si scelga in ogni intervallo un punto interno a e si definisce la somma integrale: Ponendo e il massimo e il minimo di in ogni intervallo si costruiscono quindi le somme: All’aumentare di , si ha che diminuisce e cresce. Essendo allora le due successioni monotone, esse ammettono un limite, il quale è finito. Sia ora: Si ha che: Per il teorema di esistenza del limite di successioni monotone risulta e , con . All’affinarsi della partizione di risulta , infatti è possibile fissare un piccolo a piacere e un numero di suddivisioni della partizione sufficientemente grande da far risultare: poiché per la continuità uniforme di si ha: Cioè, per un numero di suddivisioni abbastanza elevato: Per il teorema del confronto delle successioni si ha: ossia: da cui, data l’arbitrarietà del fattore , risulta che con il passaggio al limite la differenza tra le somme integrali massimante e minimante tende a zero. Da questo segue che: In definitiva, essendo: per il teorema del confronto risulta , da cui si deduce che se la funzione integranda è continua su un compatto allora l’operazione di integrazione non dipende dalla scelta dei punti interni agli intervalli , ovvero la funzione è integrabile. |
Una funzione si dice assolutamente integrabile su un intervallo aperto del tipo se su tale intervallo è integrabile . Non tutte le funzioni integrabili sono assolutamente integrabili: un esempio di funzione di questo tipo è . Viceversa, il teorema sull’esistenza degli integrali impropri all’infinito garantisce che una funzione assolutamente integrabile sia integrabile su un intervallo del tipo .
| Dimostrazione |
|---|
| Infatti, una condizione necessaria e sufficiente affinché esista finito è che per ogni esista tale che per ogni si abbia:
Sostituendo in quest’ultima espressione con la condizione di esistenza diventa: da cui si ha: e quindi si può scrivere: Si ricava così che è integrabile. |
Il teorema di Vitali-Lebesgue è un teorema che consente di individuare le funzioni definite su uno spazio che siano integrabili secondo Riemann. Fu dimostrato nel 1907 dal matematico italiano Giuseppe Vitali contemporaneamente e indipendentemente con il matematico francese Henri Lebesgue.
Data una funzione su che sia limitata e nulla al di fuori di un sottoinsieme limitato di , essa è integrabile secondo Riemann se e solo se è trascurabile l’insieme dei suoi punti di discontinuità. Se si verifica questo, la funzione è anche integrabile secondo Lebesgue e i due integrali coincidono. Nel caso in cui l’enunciato assume la seguente forma: una funzione limitata in un intervallo è ivi integrabile secondo Riemann se e solo se l’insieme dei suoi punti di discontinuità è di misura nulla rispetto alla misura di Lebesgue
Il teorema fondamentale del calcolo integrale, grazie agli studi e alle intuizioni di Leibniz, Newton, Torricelli e Barrow, stabilisce la relazione esistente tra calcolo differenziale e calcolo integrale.
Esso è generalizzato dal fondamentale teorema di Stokes.
Il problema inverso a quello della derivazione consiste nella ricerca di tutte le funzioni la cui derivata sia uguale a una funzione assegnata. Questo problema è noto come ricerca delle primitive di una funzione. Nel caso in cui sia una primitiva di (cioè se ) allora, poiché la derivata di una funzione costante è nulla, anche una qualunque funzione del tipo:
che differisca da per una costante arbitraria , risulta essere primitiva di . Infatti:
Quindi, se una funzione ammette primitiva allora esiste un’intera classe di primitive del tipo:
Viceversa, tutte le primitive di sono della forma .
La totalità delle primitive di una funzione si chiama integrale indefinito di tale funzione. Il simbolo:
denota l’integrale indefinito della funzione rispetto a . La funzione è detta anche in questo caso funzione integranda. In un certo senso (non formale), si può vedere l’integrale indefinito come “l’operazione inversa della derivata”. Tuttavia, da un punto di vista formale, la derivazione non è iniettiva e quindi non è invertibile e l’operatore integrale restituisce l’insieme delle primitive che o è vuoto oppure contiene infiniti elementi.
Ogni funzione continua in un intervallo ammette sempre integrale indefinito, ma non è detto che sia derivabile in ogni suo punto. Se è una funzione definita in un intervallo nel quale ammette una primitiva allora l’integrale indefinito di è:
dove è una generica costante reale.
Sia una funzione definita su un intervallo . Se la funzione è integrabile su ogni intervallo chiuso e limitato contenuto in , al variare dell’intervallo varia il valore dell’integrale. Si ponga , dove è fissato e l’altro estremo è variabile: l’integrale di su diventa allora una funzione di . Tale funzione si dice funzione integrale di o integrale di Torricelli, e si indica con:
La variabile di integrazione è detta variabile muta, e varia tra e .
La prima parte del teorema è detta primo teorema fondamentale del calcolo, afferma che la funzione integrale (come sopra definita)
è una primitiva della funzione di partenza.
Cioè
La seconda parte del teorema è detta secondo teorema fondamentale del calcolo, e consente di calcolare l’integrale definito di una funzione attraverso una delle sue primitive.
e tale relazione è detta formula fondamentale del calcolo integrale.
Sia un intervallo, funzione di classe in e curve di classe . Sia la funzione integrale di classe definita come:
Di seguito si riportano le proprietà principali dell’operatore integrale.
Siano e due funzioni continue definite in un intervallo e siano . Allora:
| Dimostrazione |
|---|
| Infatti, dalla definizione si ha che:
da cui: Dalla proprietà distributiva e dal fatto che il limite della somma coincide con la somma dei limiti si ha: da cui discende la proprietà di linearità. |
Sia continua e definita in un intervallo e sia . Allora:
| Dimostrazione |
|---|
| Infatti, dalla definizione si ha che:
da cui se si ha esistono un valore e un valore la cui somma è tali che per un affinamento sufficiente della partizione risulti: Distribuendo la misura dell’intervallo: in cui . Considerando l’intervallo , l’indice può essere riscritto come in quanto è il valore superiore del primo intervallo della partizione di . Ricordando che: risulta allora: da cui discende la proprietà di additività. |
Siano e due funzioni continue definite in un intervallo e tali che in . Allora:
| Dimostrazione |
|---|
| Infatti, se si verifica che nel compatto , effettuando una partizione di tale intervallo la disuguaglianza permane e moltiplicando da ambo i lati per il fattore si ottiene:
per ogni . A questo punto se la relazione è valida per qualsiasi intervallo in cui è suddiviso il compatto vale la seguente: Come conseguenza del corollario del teorema della permanenza del segno dei limiti, applicando il limite alle somme integrali di Riemann (ottenendo quindi l’integrale) la disuguaglianza resta immutata: Da ciò deriva la proprietà di monotonia degli integrali. |
Tale teorema si potrebbe considerare come un corollario del teorema del confronto. Se è integrabile in un intervallo si ha:
| Dimostrazione |
|---|
| Infatti, essendo valida la relazione per ogni s, è possibile sommare membro a membro le varie componenti della relazione, ottenendo:
Moltiplicando ogni membro per il fattore e applicando il limite in modo da affinare gli intervalli della partizione si ottengono gli integrali: ove quest’ultima disuguaglianza può essere espressa in termini di valore assoluto come: la quale è la proprietà del valore assoluto degli integrali. |
Se è continua allora esiste tale che:
Un integrale improprio è un limite della forma:
oppure:
Un integrale è improprio anche nel caso in cui la funzione integranda non è definita in uno o più punti interni del dominio di integrazione.
L’integrazione di una funzione reale è un calcolo matematico di non semplice risoluzione generale. Il caso più semplice si ha quando si riconosce la funzione integranda essere la derivata di una funzione nota . In casi più complessi esistono numerosi metodi per trovare la funzione primitiva. In particolare, tra le tecniche più diffuse per la ricerca della primitiva dell’integranda sono queste due:
Un metodo che consente di ottenere la stima asintotica di una somma è l’approssimazione di una serie tramite il suo integrale. Sia una funzione monotona non decrescente. Allora per ogni e ogni intero si ha:
Infatti, se la proprietà è banale, mentre se si osserva che la funzione è integrabile in ogni intervallo chiuso e limitato di , e che per ogni vale la relazione:
Sommando per si ottiene dalla prima disuguaglianza:
mentre dalla seconda segue che:
Aggiungendo ora e alle due somme precedenti si verifica la relazione.
Sono state sviluppate altre definizioni di integrale, alcune delle quali sono dovute a Denjoy, Perron, Henstock e altri.
I tre nominati condividono la validità del teorema fondamentale del calcolo integrale in una forma più generale rispetto alla trattazione di Riemann e Lebesgue.
Il primo in ordine cronologico a essere introdotto è stato l’integrale di Denjoy, definito per mezzo di una classe di funzioni che generalizza le funzioni assolutamente continue.
Successivamente, solo due anni dopo, Perron ha dato la sua definizione con un metodo che ricorda le funzioni maggioranti e minoranti di Darboux.
In ultimo, Ralph Henstock e (indipendentemente) Jaroslaw Kurzweil forniscono una terza definizione equivalente, detta anche integrale di gauge: essa sfrutta una leggera generalizzazione della definizione di Riemann, la cui semplicità rispetto alle altre due è probabilmente il motivo per cui questo integrale è più noto con il nome del matematico inglese che con quelli di Denjoy e Perron.
In analisi matematica, l’integrale di Henstock-Kurzweil è una possibile definizione di integrale per una funzione di variabile reale.
Il concetto è stato introdotto indipendentemente da Ralph Henstock e da Jaroslaw Kurzweil a partire dal 1957.
È noto anche come integrale di gauge o come integrale di Riemann generalizzato, in quanto la sua definizione è portata avanti come generalizzazione di quella dell’integrale di Riemann.
Questo risultato generalizza infatti i corrispondenti teoremi riguardanti Riemann e Lebesgue perché l’integrabilità della derivata è una tesi, non una ipotesi.
La sua definizione era però particolarmente complicata, perché faceva uso della nozione di induzione transfinita per gestire le singolarità che entravano in gioco.
La definizione originale è data per funzioni definite su intervalli compatti a valori reali. Come per l’integrale di Riemann, si lavora con partizioni dell’intervallo . A differenza di quest’ultimo, però, la scelta dei punti interni ad ogni sottointervallo della partizione non è arbitraria, ma deve soddisfare un’ulteriore ipotesi di regolarità. Infatti saranno ammissibili per formare una somma di Riemann solo partizioni che, insieme con un certo numero di punti di scelta , soddisfano un criterio detto di -finitezza, che si enuncia come
dove è una funzione strettamente positiva definita su . La coppia punti di scelta-sottointervalli si dice per brevità una partizione puntata -fine e la funzione una gauge.
A questo punto si può dire che:
Il primo termine della disuguaglianza sopra è esattamente la somma di Riemann di relativa ai punti e agli intervalli ( rappresenta la misura dell’intervallo ). Notiamo infatti che tale definizione è quasi uguale a quella di Riemann; le differenze si limitano al sostituire una costante positiva con una funzione positiva e la condizione “mesh minore di ” con quella di “-finitezza”.
Questa generalizzazione, che potrebbe sembrare leggera, in realtà è fondamentale, perché corrisponde all’idea di poter definire un per ogni punto di e quindi alla possibilità di approssimare meglio il comportamento della funzione, in zone dove essa abbia un comportamento più “patologico” perché molto oscillatorio, o perché essa presenta un asintoto, mediante partizioni localmente più raffinate.
La definizione si basa sulla proprietà di -finitezza di una partizione puntata, ma l’assenza totale di ipotesi sulla funzione potrebbe far nascere dei dubbi riguardo all’esistenza di partizioni -fini per gauge “bizzarre”.
Fortunatamente un lemma dovuto a Pierre Cousin, addirittura del secolo precedente quindi non collegato alla teoria dell’integrazione, assicura proprio che partizioni -fini esistano per ogni funzione positiva .
La dimostrazione di questo risultato non è banale, perché coinvolge la completezza dei reali, quindi questo può caratterizzarsi come un piccolo punto debole della teoria.
Molto meno immediato, ma forse più importante, è che l’integrale di Henstock-Kurzweil estende anche l’integrale di Lebesgue, assicurando così una base di funzioni integrabili molto ampia, che include molte funzioni di grande importanza nelle applicazioni.
Inoltre, valgono come per l’integrale di Lebesgue i teoremi di convergenza monotona e dominata.
Una differenza rispetto a quest’ultimo è però che l’integrabilità di una funzione non implica quella del suo valore assoluto. Si verifica infatti che, se una funzione è integrabile, il suo modulo è anch’esso integrabile se e solo se la sua funzione integrale è a variazione limitata.
Da questa limitazione deriva un lato in prima analisi negativo della teoria, cioè che lo spazio funzionale delle funzioni integrabili su un determinato dominio è sì uno spazio vettoriale, ma non è stata trovata una norma che lo renda di Banach.
Particolarmente usata su risulta la norma di Alexiewicz
Tale funzione soddisfa le proprietà di una norma quando vengono identificate due funzioni uguali quasi ovunque (altrimenti è una seminorma), come nella teoria di Lebesgue.
La costruzione di Henstock e Kurzweil risolve anche un altro lato negativo dell’integrale di Riemann, cioè il problema dell’integrazione impropria: dando infatti una appropriata definizione di gauge su un intervallo illimitato, si verifica il seguente risultato:
È da sottolineare che la precedente formula, che nell’integrale di Riemann era una definizione, in questa teoria è una tesi. Questo teorema (che si può adattare anche per l’altra tipologia di integrale improprio) è dovuto a Heinrich Hake.
Enunciato del lemmaSia un processo di Itō (o processo di Wiener generalizzato); in altre parole, soddisfa l’equazione differenziale stocastica:
Sia inoltre una funzione , avente derivata seconda continua. Allora:
Giustificazione informale del risultatoTramite un’espansione in serie di Taylor di si ottiene:
Sostituendo dalla SDE sopra si ha:
Lo sviluppo in serie di Taylor viene di solito troncato al primo ordine; già questo consente una buona approssimazione della funzione di partenza. In questo caso, bisogna considerare che i termini in vanno come quelli in ; avendo lo stesso ordine di grandezza troncando al primo ordine, devono essere considerati anche i termini in . Passando al limite per tendente a 0, i termini scompaiono. Infatti, nei limiti infinitesimi (a zero) prevale la potenza con esponente più basso, che arriva a zero più lentamente degli altri termini. Per contro tende a ; quest’ultima proprietà può essere dimostrata provando che:
Sostituendo questi risultati nell’espressione per si ottiene:
come richiesto. Una dimostrazione formale di questo risultato richiede la definizione di un integrale stocastico.
Funzione cilindrica

Funzione Gamma
dove denota il fattoriale di cioè il prodotto dei numeri interi da a : .

La notazione è dovuta a Legendre.
Se la parte reale del numero complesso è positiva, allora l’integrale
converge assolutamente. Comunque, usando la continuazione analitica, si può estendere la definizione della a tutti i numeri complessi , anche con parte reale non positiva, ad eccezione degli interi minori o uguali a zero. Usando l’integrazione per parti, in effetti, si può dimostrare che:
per cui si ha:
In questo modo, la definizione della può essere estesa dal semipiano a quello (ad eccezione del polo in ), e successivamente a tutto il piano complesso (con poli in ).
Siccome , la relazione riportata sopra implica, per tutti i numeri naturali , che:
In statistica si incontra di frequente (per esempio nella variabile casuale normale) l’integrale:
che si ottiene ponendo , e quindi , ottenendo quindi
Le seguenti espressioni alternative per la funzione Gamma, sono valide su tutto il piano complesso (ad eccezione dei poli):
dovuta a Gauss,
dove è la costante di Eulero-Mascheroni, dovuta a Schlömilch e ottenibile applicando il teorema di fattorizzazione di Weierstrass alla funzione
Un’ulteriore espressione alternativa è la seguente:
In questa formula sono espliciti i poli di ordine e residuo che la funzione Gamma ha in , per ogni intero non negativo.
La singolarità nell’origine può essere anche dedotta dalla relazione di ricorrenza. Infatti
dove è stato fatto uso della relazione .
Valori notevoli
Teorema di unicità
°°°°°
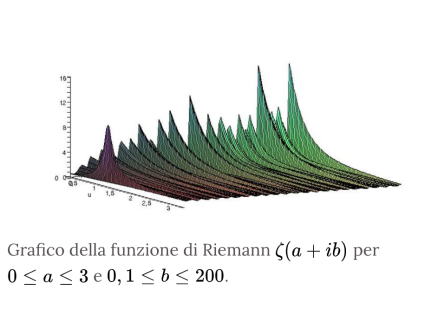


Il prodotto di Eulero
Alcune serie correlate
Equazione funzionale
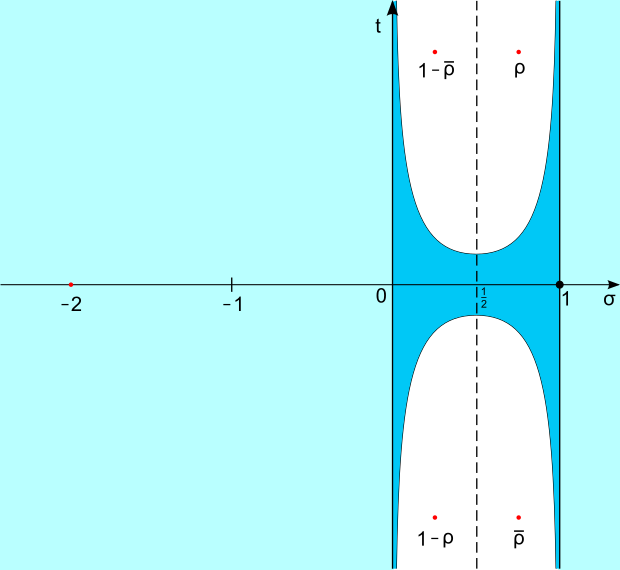

La formula di Riemann-von MangoldtNella memoria di Riemann è presente una stima asintotica per il numero di zeri non banali con parte immaginaria compresa tra e per che tende all’infinito.
Definito
dove denota la cardinalità dell’insieme, si ha
dove denota il simbolo di Landau
e
e indica l’argomento.
Questa formula, enunciata da Riemann, è stata dimostrata da von Mangoldt nel 1905 ed è nota come formula di Riemann-von Mangoldt.
È chiaro che l’ipotesi di Riemann è vera se e solo se coincide con
Sono stati ottenuti alcuni risultati parziali in questa direzione, i più importanti dei quali sono dovuti ad Hardy e Littlewood, che hanno provato che
a Selberg che ha provato che
per una qualche costante κ > 0, e a Levinson e Conrey che hanno migliorato tale costante, portandola rispettivamente a 1/3 e poco più di 2/5.
Un’altra importante congettura sulla funzione zeta di Riemann (detta congettura degli zeri semplici o, in inglese, Simple Zeros Conjecture) asserisce che tutti gli zeri della funzione sono semplici.
I risultati ottenuti a proposito della percentuale degli zeri semplici sono molto simili a quelli per la percentuale degli zeri sulla retta critica ed anche in questo caso è stato provato che
per una costante κ* > 2/5.[9][11]
Correlazione tra gli zeriDalla formula asintotica per N(T) è facile dimostrare che, assumendo l’ipotesi di Riemann, la distanza media tra due zeri consecutivi di ζ(s) ad altezza T è 2Π/logT.
Ci possono però essere intervalli insolitamente lunghi ed insolitamente corti senza zeri ed infatti, assumendo l’ipotesi di Riemann ed indicando con l’n-esimo zero non banale (di parte immaginaria positiva) della funzione zeta di Riemann, si ha che esistono due costanti λ1 < 1 e λ2 > 1 tali che
e
Un’importante congettura sugli zeri della funzione zeta di Riemann è la congettura della correlazione delle coppie di Hugh Montgomery (in inglese, pair correlation conjecture).
Questa congettura afferma che, per ogni β > α > 0, si ha
per che tende all’infinito.[14]
°°°°°
Sulla base del teorema di fattorizzazione di Weierstrass, Jacques Hadamard dimostrò che:
dove è la costante di Eulero-Mascheroni e sono gli zeri non banali della funzione zeta.

°°°°°
Si può dimostrare dalla definizione che valgono le seguenti uguaglianze, ponendo per semplicità di notazione :
Se è una variabile casuale assolutamente continua la funzione di ripartizione di può essere espressa come funzione integrale:
ove è detta funzione di densità di .
Si può anche considerare la relazione inversa:
Se è una variabile casuale discreta (ossia ammette una collezione numerabile di possibili valori )
dove è detta funzione di probabilità di .

Se è la variabile aleatoria risultato del lancio di un dado a sei facce si ha
dove con si indica la parte intera di x.
Se è la variabile casuale uniforme continua in si ha
In alcuni modelli è più utile analizzare la probabilità che un certo dato numerico valga più del valore (come nella vita di un organismo, biologico o meccanico): questi casi sono trattati dalla branca chiamata analisi di sopravvivenza. Si definisce allora la funzione di sopravvivenza (dal termine inglese survival) come il complemento della funzione di ripartizione:
Nei casi rispettivamente continuo e discreto, valgono naturalmente delle identità speculari a quelle della ripartizione:
e
Ogni funzione di sopravvivenza è una funzione monotona decrescente, vale a dire per
Il tempo rappresenta l’origine, in genere l’inizio di uno studio o l’inizio del funzionamento di alcuni sistemi.
Più in generale la funzione di ripartizione di una variabile aleatoria a valori in è la funzione con dominio e codominio l’intervallo definita da
dove sono le componenti di .
Questa funzione possiede la proprietà di essere continua a destra separatamente per ogni variabile. Valgono inoltre le seguenti formule, derivanti dalla definizione:
Da quest’ultima proprietà viene anche l’uguaglianza
e l’affermazione vale ovviamente anche per ogni permutazione degli indici .
Funzione di densità di probabilitàIn matematica , Una Funzione di densita di Probabilità (o dall’inglese PDF funzione densità di probabilità ) e L’Analogo della Funzione di Probabilità Di Una variabile Casuale nel Caso in cui la variabile Casuale SIA continua , cioè l’Insieme dei Valori Possibili Che ha la potenza del continuo . Essa descrive la “densità” di probabilità in ogni punto nello spazio campionario .

Funzione generatrice dei momenti
 definita su un dominio
definita su un dominio  che sia derivabile parzialmente due volte e che soddisfi l’equazione di Laplace, cioè tale che
che sia derivabile parzialmente due volte e che soddisfi l’equazione di Laplace, cioè tale che
 , è armonica. Infatti
, è armonica. Infatti

 e sia
e sia  una funzione armonica.
una funzione armonica. il volume della palla unitaria in
il volume della palla unitaria in  .
. , vale la seguente uguaglianza:
, vale la seguente uguaglianza:

 . Applicando il teorema della divergenza al campo vettoriale
. Applicando il teorema della divergenza al campo vettoriale  si ottiene
si ottiene
 .
.




 si ottiene la prima uguaglianza. La seconda si ottiene integrando rispetto a ρ. una funzione armonica, dove è un dominio di
si ottiene la prima uguaglianza. La seconda si ottiene integrando rispetto a ρ. una funzione armonica, dove è un dominio di  .
. in tale che
in tale che  per ogni
per ogni  . Allora
. Allora  è costante.
è costante. e si consideri l’insieme
e si consideri l’insieme  . per la continuità di .
. per la continuità di . . Essa è negativa ed armonica.
. Essa è negativa ed armonica. e si applichi la proprietà del valor medio a .
e si applichi la proprietà del valor medio a .
 nella palla
nella palla  .
. , cioè
, cioè  è aperto in .
è aperto in . .
.



iMathematica :
più La si visita più Vi aiuta a risolvere ... iProblemi ...!

















































































































































































































































































![I=[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d6214bb3ce7f00e496c0706edd1464ac60b73b5)


![x \in [a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/026357b404ee584c475579fb2302a4e9881b8cce)


















![f:[a,b]\rightarrow \mathbb{R}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc0d2d0b70573525d149ab82948308455d1853d0)








































![[-aa]](https://wikimedia.org/api/rest_v1/media/math/render/svg/50ccbcece37f9ec0a4c6d396be3a143a0b76d5c1)
![{\ displaystyle [0, a]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/63d050b0ffe6cc6f635808b9a013366a60e6d0c0)




















































































![A[x_{1},\ldots ,x_{n}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9878551d3c43d5d887ee0230a5eb2ab1abe2bcfe)


![\mathbb {Z} [x]](https://wikimedia.org/api/rest_v1/media/math/render/svg/0d4da3ac703cc7721ebba91a53f6752de7157124)

![\mathbb {R} [x,y]](https://wikimedia.org/api/rest_v1/media/math/render/svg/de78aea249c4a765d912587db125dfdbacc3d432)
![K[x]](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a9e6c2ac2830d6a9abe078b47450777c41d69a9)
















































































![{\displaystyle \mathbf {L} (\mathbf {x} )\mathbf {h} =\sum _{i=1}^{m}\left[\sum _{j=1}^{n}{\frac {\partial F_{i}(\mathbf {x} )}{\partial x_{j))}h_{j}\right]\mathbf {u} _{i}=J_{F}\mathbf {h} ={\begin{bmatrix}{\dfrac {\partial F_{1)){\partial x_{1))}&\cdots &{\dfrac {\partial F_{1)){\partial x_{n))}\\\vdots &\ddots &\vdots \\{\dfrac {\partial F_{m)){\partial x_{1))}&\cdots &{\dfrac {\partial F_{m)){\partial x_{n))}\end{bmatrix))\mathbf {h} .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/01ffca52ee4784256614c1f820250156691ef260)


























































































































![[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)







![{\displaystyle [x_{k-1},x_{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f77539e232b976d1a83e1829624235bba4164757)








![{\displaystyle {\mathcal {R))=\{(x,y)\in \mathbb {R} ^{2},\,0\leq y\leq f(x),x\in [a,b]\}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bddcd6038f92f9c2bd61b881764bc2efcc234f3a)


![PC[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b1be1f04552b49f5f59b0db31783c77138cd9b3)

![{\displaystyle \|f\|_{\infty }=\sup _{x\in [a,b]}|f(x)|.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/852a678d206c6870a134228daf5682284d82b09c)


![[x_((i-1)),x_{i}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/09cb12a889d47020c8ce7046a2eb60785e00c0b6)
![S[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/ae911ae7a3fd00feb05a6d3c0cf0d78eec8bc712)
![{\displaystyle \|\sum _{i=1}^{n}c_{i}\chi _{i}(x)\|_{\infty }=\sup _{x\in [a,b]}|\sum _{i=1}^{n}c_{i}\chi _{i}(x)|=\max _{i=1,\dots ,n}|c_{i}|\qquad c_{i}\in \mathbb {R} .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/72eb61e8909581681e61e24d8fc60ca0d6916c9b)
![I:S[a,b]\to \mathbb{R}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58944acc0fd1b885dd0f770e5de529e4160979de)
![{\displaystyle I\left[\sum _{i=1}^{n}c_{i}\chi _{i}(x)\right]=\sum _{i=1}^{n}c_{i}(x_{i}-x_{i-1}).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dd1ec257063cce8eb410d4c1497458e1c5ccaec7)

![{\hat S}[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/27dff51cb7580b01add1c586172814be7b49f9c3)
![{\displaystyle {\hat {I))\colon {\hat {S))[a,b]\to \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/27e1a973047691204b657c53d8caaa1a17712115)










![[0,\infty ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/52088d5605716e18068a460dec118214954a68e9)














![[a_((j+1)),b_((j+1))]](https://wikimedia.org/api/rest_v1/media/math/render/svg/295494b4f541a3b833f797b4a7bf35648df67044)

















![t\in [a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/b7f3050ace6dc0dd95250c418528da28eb477ffe)


![[r(a),r(b)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/0adcd6bce50edb796dfb92b2bc3782eab79a065c)














































![J=[x_{0},x]](https://wikimedia.org/api/rest_v1/media/math/render/svg/967bd8de5b7630c12bc3e49d2d643b3a5e9b7802)












![{\displaystyle \int _{a}^{b}[\alpha f(x)+\beta g(x)]\,\mathrm {d} x=\alpha \int _{a}^{b}\!f(x)\,\mathrm {d} x+\beta \int _{a}^{b}\!g(x)\,\mathrm {d} x.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/00775f96864e109ff28ea9eb73e1733de687076a)
![{\displaystyle \int _{a}^{b}[\alpha f(x)+\beta g(x)]\,\mathrm {d} x=\lim _{n\to +\infty }((b-a} \over {n))\sum _{s=1}^{n}\,[\alpha f(t_{s})+\beta g(t_{s})],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9604a70b21255aff7a2bd2f2771c554fd7b784cf)
![{\displaystyle \int _{a}^{b}[\alpha f(x)+\beta g(x)]\,\mathrm {d} x=\lim _{n\to +\infty }((b-a} \over {n))[\alpha \sum _{s=1}^{n}f(t_{s})+\beta \sum _{s=1}^{n}g(t_{s})].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/623cc1ea857dbe5f149d66ef1030708d945b4136)
![{\displaystyle \int _{a}^{b}[\alpha f(x)+\beta g(x)]\,\mathrm {d} x=\alpha \lim _{n\to +\infty }((b-a} \over {n))\sum _{s=1}^{n}f(t_{s})+\beta \lim _{n\to +\infty }((b-a} \over {n))\sum _{s=1}^{n}g(t_{s})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b41150f76bbe56156e2e16f94f2ec947c2bb1580)
![[a,c]](https://wikimedia.org/api/rest_v1/media/math/render/svg/70b45aa26fb924cdd37786af1adcf5d58cfe15af)
![b\in [a,c]](https://wikimedia.org/api/rest_v1/media/math/render/svg/55e3f4eae30b0446923985138a5d42245d109988)


![c\in [a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/997256364b06acf0710e5d24da39e8c42991a249)




![{\displaystyle [c,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/07f3f774df12e18b9f2bb94333ff320bbd2c308d)







![\ [a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f4c40bbeaa2f59e60b6259cebe2479bc24396f0)










![f:[a,b]\to {\mathbb R}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b592d102ccd1ba134d401c5b3ea177baaba3ffac)


















![{\displaystyle f\colon [a,b]\to \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/c5ab61178bf5349838758ffe3d96135406ed0245)










![{\displaystyle f\colon [a,+\infty ]\to \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/77f1bfd23383d0c9e0c693e1c694846a62db6480)
![{\displaystyle [a,+\infty ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d661f1af25e22860b7bd3947ce61039c04b4d134)

























![\int _((a))^((b))mx\,{\mathrm {d))x=\left[((mb^((2))} \over {2))+c\right]-\left[((ma^((2))} \over {2))+c\right]=m((b^{2}-a^{2)) \over {2))](https://wikimedia.org/api/rest_v1/media/math/render/svg/6150e38fec3c3fb43ca82516f455e9a7618d139c)







![f(x_((i)))=m\left[a+i((b-a} \over {n))\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/15c32285163ea637fd98607078c8889b85882a84)
)=ma(b-a)+m\left(((b-a} \over {n))\right)^{2}\sum _{i=1}^{n}i}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d7fefa3677bf6c8bf0a53fd43cc78c138da65bf8)












































![{\displaystyle \Gamma ^{(n)}(z)=\int _{0}^{+\infty }[\ln {(t)}]^{n}\,t^{z-1}\,e^{-t}\,dt}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f642585e2f3ff3e135f18f3ae870b0d6992ccaee)









![{\displaystyle \left[{\frac {d}{dz)){\frac {\Gamma '{(z))){\Gamma {(z)))}\right]_{z=1}=\psi _{1}(1)=\sum _{n=0}^{\infty }{\frac {1}{(n+1)^{2))}=\sum _{n=1}^{\infty }{\frac {1}{n^{2))}=\zeta (2)={\frac {\pi ^{2)){6))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a426d25fac1a62bca27f601d134d24696c3ea039)





















































![\left\{\gamma ,\gamma '\in [0,T]\mid \zeta \left({\frac 12}+\gamma \right)=0,\zeta \left({\frac 12}+\gamma '\right)=0,\ {\frac {2\pi \alpha }{\log T))\leq \gamma -\gamma '\leq {\frac {2\pi \beta }{\log T))\right\}\sim N(T)\int _{\alpha }^{\beta }\left(1-\left({\frac {\sin \pi u}{u))\right)^{2}\right)\,du,](https://wikimedia.org/api/rest_v1/media/math/render/svg/438fe51ac9ac7c0e1c9f60e5671170832b4fa0c2)
































![F\colon \mathbb{R} \to [0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d554e9659b1b9888629676b3c070ca42d86ecfca)
![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)


















































![p_{X}:\mathbb{R} \longrightarrow [0,1],\,p_{X}(x)={\begin{cases}P(X=x),&x\in S,\\0,&x\in {\mathbb {R))\backslash S.\end{cases))](https://wikimedia.org/api/rest_v1/media/math/render/svg/3dd3f3e2a3b10defa322212ffae0e57ecd475ecc)













![{\ displaystyle [x, x + \ mathrm {d} x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2497bba0513a671ec5bbc5074589b01eb03b3374)













![\ g (t) = \ mbox {E} [e ^ {tX}] = \ sum_ {i = 1} ^ {n} p_ {i} e ^ {tX_ {i))](https://wikimedia.org/api/rest_v1/media/math/render/svg/ce000376e92c1657dec723bae08255da19305ea5)
![\ g (t) = \ mbox {E} [e ^ {tX}] = \ int _ {- \ infty} ^ {\ infty} e ^ {tx} f_ {X} (x) dx](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c4e713496ea76ef43540e7a6a2878497ab89eff)


















![\operatorname {E}\left(X^{n}\right)=(-i)^{n}\,\phi _{X}^(((n)))(0)=(-i)^{n}\,\left[{\frac {d^{n)){dt^{n))}\phi _{X}(t)\right]_((t=0)).](https://wikimedia.org/api/rest_v1/media/math/render/svg/efce42381270f2998c35b5b6eab4b0fa35572f23)




Devi effettuare l'accesso per postare un commento.